Time in Distributed Systems
Confusion that never stops, Closing walls and ticking clocks


Just like Rob’s dilemma in High Fidelity, what came first in distributed systems is an hard question to answer. This is because coming to an agreement on what time it is now in a network of computers is difficult.
In this post, I want to discuss the two kinds of time that are relevant when we talk about distributed systems, the characteristics of both, the different kinds of problems that they solve and their usage in real world distributed systems.
We will discuss:
Physical time
Logical time
How Dynamo and other dynamo like systems use vector clocks
How Spanner provides the highest level of consistency using Truetime API
Physical Time or Wall Clock
The first kind of time is time as we know it, the time we get by looking at a clock. In most cases, a process on a computer finds the physical time using the gettimeofday() system call. Physical time on a machine is usually calculated with the help of quartz crystals that vibrate at known frequencies when electricity is applied to them. Like with everything you get what you pay for.
In an ideal world, all the machines would be perfectly synchronized since that would give us a mechanism to order events no matter what node they originated in. For a more detailed treatment of how synchronized clocks make a lot of distributed algorithms easier, look at this paper from Barbara Liskov. Our world is far from perfect though and locks in different machines can gloriously go out of sync. Hence the need for clock synchronization algorithms.
Most clock synchronization algorithms work on probabilistic assumptions about clock rate and message delay. So they synchronize clocks with some skew epsilon i.e. they guarantee that if c1 and c2 are clocks on two nodes of the network the difference between the time at c1 and the time at c2 does not differ by more than epsilon with some very high probability.
The most popular synchronization algorithm is NTP which is used to bring a computer’s clock to within a few milliseconds of UTC. (Sidenote: Whenever needed to make a choice of a timezone, always use UTC.)
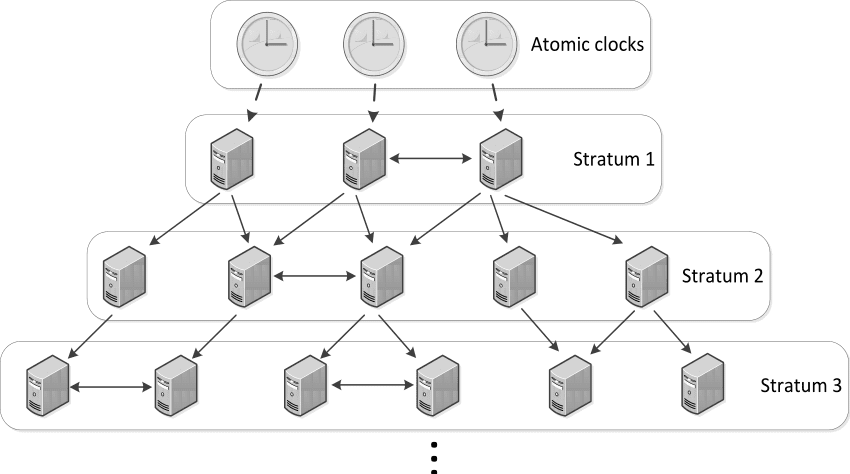
NTP uses a strata of clocks with the lowest stratum time server (stratum = 0) synchronized with a high quality clock such as an atomic clock or GPS. NTP also has to deal with leap seconds. Leap seconds are 1 second adjustments that need to be applied to UTC to make sure it doesn’t fall out of sync with observed Solar Time. The default is to pause the clock for a while but smearing the leap second over 24 hours is becoming more popular and is used by both Google and Amazon.
Even with a functioning NTP running on your servers, the skew between locks range from anywhere between 100 -250 ms. There are certain algorithms which can provide tighter skews at the cost of not being internet scale such as PTP, which is used in the High Frequency Trading world. There is also the Google TrueTime service which we will be discussing a bit later while discussing use of physical clocks in real world systems.
Getting a tighter skew costs a lot more though and sometimes all we are concerned about is what happens within a distributed system. Enter Logical time.
Logical time and Vector Clocks
Let’s say we want to determine the order of events within a distributed system. We can use physical clocks, but as we just discovered physical clocks are not a panacea. So is it even possible to define what happens before what without using physical clocks.
This is exactly what Leslie Lamport covered in his seminal paper Time, Clocks, and the Ordering of Events in a Distributed System. Lamport defines his world of distributed systems as n nodes running and exchanging messages with each other. He then defines the happened before relationship ‘→’ as follows.
(1) If a and b are events in the same node, and a comes before b, then a → b.
(2) If a is the sending of a message by one node and b is the receipt of the same message by another node, then a → b.
(3) If a → b and b → c then a → c.
Two distinct events a and b are said to be concurrent if we cant say whether a happened before b or b happened before a.
He then introduced the concept of a clock, where the clock is an arbitrary number assigned to an event. The Lamport clock condition L is as follows.
If a → b then L(A) > L(B).
These clocks, also known as Lamport Clocks, therefore can be implemented as monotonically increasing integers which are incremented on every operation in a node.

While Lamport clocks give us a way to capture potential causality they are very limited. If L(A) < L(B) then the only thing we can say for sure is that B did not cause A. They do not help us understand whether A and B were concurrent.
To solve this, vector clocks were introduced which are a generalisation of Lamport clocks where each node tracks the maximum Lamport clock that it knows of, of every other node.

Checking the happened before relationship between two events x and y translates to checking if each entry in the vector of x is smaller or equal to the corresponding entry in the vector of y and one is strictly smaller. If not, they are concurrent.
The authors of this article provide another way of thinking about vector clocks in terms of tracking causal histories.
Causality can be tracked in a very simple way by using causal histories. The system can locally assign unique names to each event (e.g., node name and local increasing counter) and collect and transmit sets of events to capture the known past.
For a new event, the system creates a new unique name, and the causal history consists of the union of this name and the causal history of the previous event in the node. For example, the second event in node C is assigned the name c2, and its causal history is Hc = {c1, c2}(shown in figure 2). When a node sends a message, the causal history of the send event is sent with the message. When the message is received, the remote causal history is merged (by set union) with the local history.
In our example, here’s how the tracking of causal histories would look like.

The astute reader might notice that Vector Clocks are essentially a compact encoding of causal histories.
This article provides a thorough treatment of vector clocks if you are interested in looking into them more.
I should mention there is a huge class of algorithms called consensus algorithms such as Paxos, Viewstamped Replication, Zab/Zookeeper, and Raft. They also provide ways of defining an ordering of events across a distributed system even though physical time cannot safely be used for that purpose. I intend to discuss this soon in a futue blog post.
Vector Clocks are great if all we want to do is to track order of events within a system, but the moment we want to introduce an observer outside the confines of the distributed system (for example a client), the limitations of vector clocks becomes quite apparent. Katy Perry captures the limitations of vector clocks very well in the following lyrics.

There are things which only make sense in the realm of physical time. One such example is the concept of failure of a node. Typically we say a node has ‘crashed’ when the client has been waiting too long for a response. Too long is a concept that only exists in physical time. Without physical time it’s impossible to say whether a node is dead or merely pausing before doing its next thing.
Another such concept where physical time is necessary is the concept of external consistency while talking about transactions in a database.
“A violation “of external consistency occurs when the ordering of operations inside a system does not agree with the order a user expects.”
Or in other words, External Consistency basically says that for two transactions T1 and T2
if T2 starts to commit after T1 finishes committing, then the timestamp for T2 is greater than the timestamp for T1.
External consistency is a tighter guarantee than the C promised in CAP because its defined for transactions whereas the C in CAP is equivalent to linearizability defined only for a simple read write register and not objects.
So, we understand physical time and the problems associated with it. We understand Vector clocks and their limited applicability to certain problems. Next I want to look at how real world systems use both these concepts and the implications that they bring.
Use of Vector Clocks in Dynamo
This paper was published by Amazon in 2007. It described an unapologetically eventually consistent key value store used internally within Amazon. Eventually Amazon released this as a managed data service called DynamoDB. This paper inspired a lot of dynamo style systems such as Riak and Cassandra and is quite seminal work in the NoSQL space. I strongly recommend you read it.
For concurrent updates Dynamo as described in the paper offered two reconciliation mechanisms.
Client specific Reconciliation where when conflicting versions were detected the responsibility to resolve them was passed to the client application.
Last write wins reconciliation where the object with the biggest physical timestamp is retained as the latest version.
The client specific reconciliation uses vector clocks to detect when divergent versions of an object exist.
“Dynamo uses vector clocks in order to capture causality between different versions of the same object. A vector clock is effectively a list of (node, counter) pairs. One vector clock is associated with every version of every object. One can determine whether two versions of an object are on parallel branches or have a causal ordering, by examine their vector clocks. If the counters on the first object’s clock are less-than-or-equal to all of the nodes in the second clock, then the first is an ancestor of the second and can be forgotten. Otherwise, the two changes are considered to be in conflict and require reconciliation. In Dynamo, when a client wishes to update an object, it must specify which version it is updating. This is done by passing the context it obtained from an earlier read operation, which contains the vector clock information. Upon processing a read request, if Dynamo has access to multiple branches that cannot be syntactically reconciled, it will return all the objects at the leaves, with the corresponding version information in the context. An update using this context is considered to have reconciled the divergent versions and the branches are collapsed into a single new version”
The diagram below shows an example of this might work.
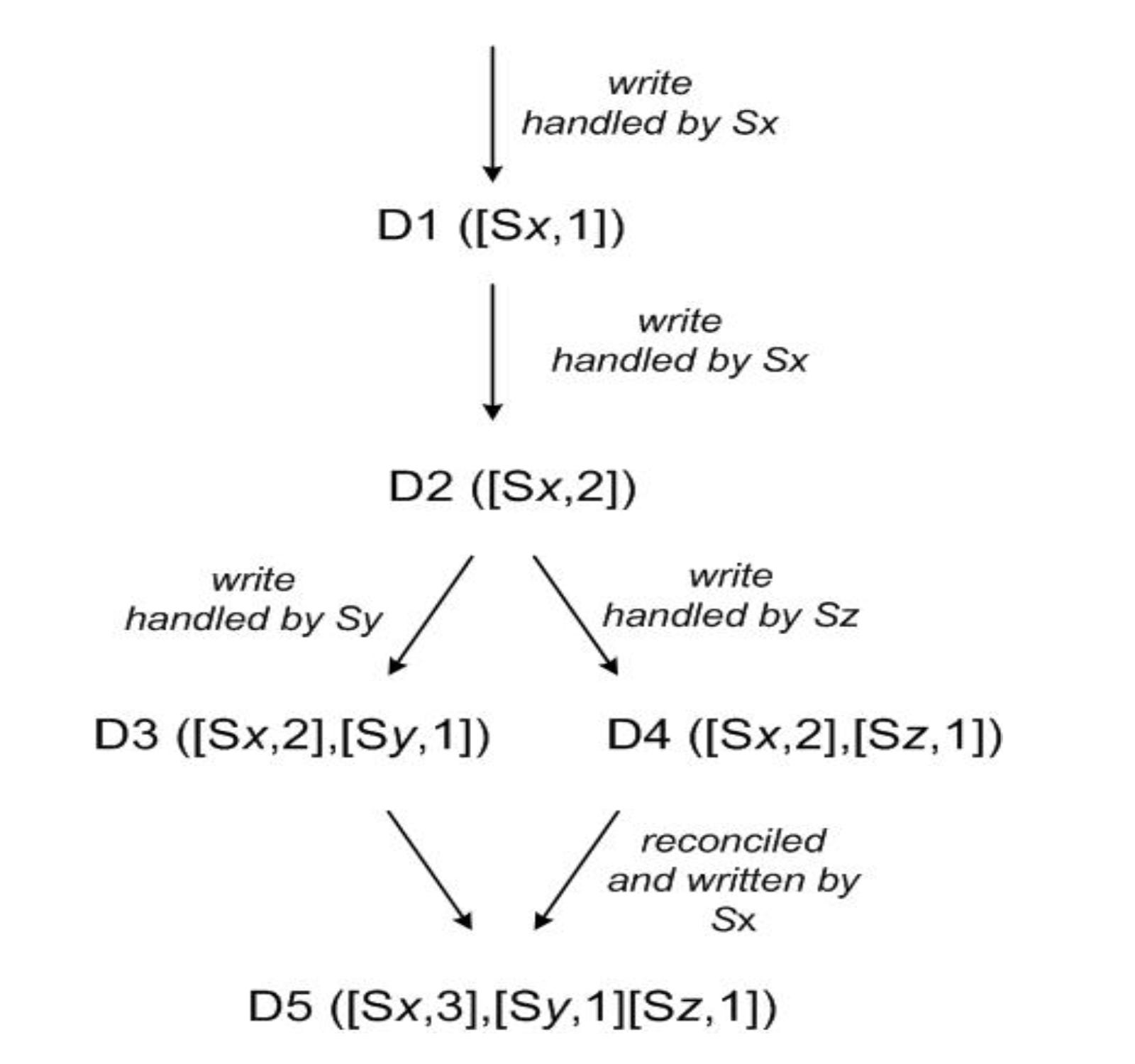
This concept was also borrowed in other dynamo style systems, most notably Riak. The problem with using vector clocks is that you might end up with a very large number of concurrent versions or siblings as riak calls them and you will need to trim them and its critics argue that this is unnecessarily complicated.
The publicly available version of DynamoDB only seems to have the last writer wins reconciliation mechanism so it seems like the critics (most notably Cassandra) can feel justified in their opinions.
Spanner and TrueTime
Spanner is Google’s highly scalable globally replicated database. It’s unique in providing external consistency guarantees at a global scale. One of the key aspects of its design is the Truetime API which explicitly exposes the uncertainty around time.
The TrueTime API has 3 methods
TT.now: This returns an interval [min, max] in which the absolute time at which this function was invoked truly lies.
TT.after(t): Returns true if the time is definitely after t.
TT.before(t): Returns true if time is definitely before t.
The Truetime API provides much tighter guarantees around the uncertainty of time than NTP does. The uncertainty in Truetime is around 7 ms, the equivalent of NTP has an upper bound of 250ms. Truetime achieves its tight time bounds by using underlying time resources of GPS and atomic clocks which provide highly accurate time.
With the uncertainty of time being so tight, Spanner achieves external consistency with a very simple trick which it calls commit wait. Let’s revisit the definition of external consistency again
if T2 starts to commit after T1 finishes committing, then the timestamp for T2 is greater than the timestamp for T1.
In Spanner, for every transaction, a node assigns a commit time to the transaction which is the upper bound of the TT.now() call. Before a node is allowed to communicate that a transaction has been committed, it must wait out the uncertainty, typically around 7ms, which guarantees that we are now definitely past the commit time assigned to the transaction.
Recall that by definition the “true” start time of any competing transaction T2 will be after the commit time assigned to the original transaction. The timestamp assigned to T2 will be greater than or equal to this “true” time as it also has to wait out the uncertainty. Voila! we have external consistency. (It took me a while to wrap my head around this).
There is another system, CockroachDB, which uses this concept of uncertainty of time but on commodity hardware, to provide consistency guarantees which are second only to Spanner. From the blog
When CockroachDB starts a transaction, it chooses a provisional commit timestamp based on the current node's wall time. It also establishes an upper bound on the selected wall time by adding the maximum clock offset for the cluster \[commit timestamp, commit timestamp + maximum clock offset]. This time interval represents the window of uncertainty.
As the transaction reads data from various nodes, it proceeds without difficulty so long as it doesn't encounter a key written within this interval. If the transaction encounters a value at a timestamp below its provisional commit timestamp, it trivially observes the value during reads and overwrites the value at the higher timestamp during writes. It's only when a value is observed to be within the uncertainty interval that CockroachDB-specific machinery kicks in. The central issue here is that given the clock offsets, we can't say for certain whether the encountered value was committed before our transaction started. In such cases, we simply make it so by performing an uncertainty restart, bumping the provisional commit timestamp just above the timestamp encountered. Crucially, the upper bound of the uncertainty interval does not change on restart, so the window of uncertainty shrinks. Transactions reading constantly updated data from many nodes may be forced to restart multiple times, though never for longer than the uncertainty interval, nor more than once per node.
Since CockroachDB runs on commodity hardware running NTP, this uncertainty interval can go upto 250 ms, which sucks but this should not happen for most transactions.
That concludes our journey of time in distributed systems. As a followup, an interesting area of research in distributed systems are CRDT(Conflict free Replicated Data Types) which attempts to avoid the need to worry about time and order. They provide a kind of safety that is sometimes called strong eventual consistency: all hosts in a system that have received the same set of updates, regardless of order, will have the same state provided that the updates to the system are commutative, associative, and idempotent. The research tries to explore how expressive we can be within these constraints. I want to cover CRDTs in my journey eventually.
There were a huge amount of resources which helped me in understanding all the nuances around time. I am sure, I probably missed a nuance or two. If you want to look at them further here are the ones I recommend:
Time, Clocks and Ordering of events in a distributed system - The original paper describing Lamport clocks by Leslie Lamport
Practical uses of synchronized clocks in distributed systems - A paper by Barbara Liskov describing how one can take advantage of synchronized clocks in certain distributed algorithms
Logical Clocks are easy A handy way to understand and reason about Logical Clocks.
There is no now Another interesting article exploring the problem with time in distributed systems.
Time is an Illusion A paper exploring physical time and synchronization problem in more details.
These flamewars and discussions around the use or lack there of of vector clocks in Riak and Cassandra. Bonus: Cassandra’s comparison with DynamoDB.
If you have reached until here, please consider following me on twitter.