Service Health and Health Checks

We were talking about health check endpoints(/health) for a service in our team standup yesterday. These checks are usually used by some kind of work producer (load balancer) for example to perform checks and servers are taken out out of service if these checks fail. Like always there were roughly two camps about thinking about health checks. At one end people were fine with a simple health check which returns true. On the other hand there was the thinking that we should do more complex checks involving checking dependencies for example or more comprehensive integration tests.
I keep oscillating between these two camps. Simple health checks which return true tell you very little about the actual health of your service and are mainly there to just keep the load balancer happy. More complex checks might result in the situation where a temporary blip in a dependency ends up with all your nodes being taken out of the load balancer.
Or something like this happening.
These are the kind of outages that stay with you. Thankfully, some load balancers implement a special strategy called fail-open to deal with the case when all servers start failing health checks. This from the Amazon Builders Library.
For example, the AWS Network Load Balancer fails open if no servers are reporting as healthy. It also fails out of unhealthy Availability Zones if all servers in an Availability Zone reports unhealthy. Our Application Load Balancer also supports fail open, as does Amazon Route 53.
Anyways, there are two issues with thinking about health checks in this binary way.
The health of a service lies on a spectrum.
The perception of health needs to include the client side perspective.
Health of a service is not binary
This insight is picked almost verbatim from Cindy Sridharan's lovely essay. From the essay:
The “health” of a process is a spectrum. What we’re really interested in is the quality-of-service — such as how long it takes for a process to return the result of a given unit of work and the accuracy of the result.
The essay goes on a little beyond the point of health checks and makes some very interesting points. The key takeaways for me:
For the layer that determines whether to give traffic to a particular node or not, its more interesting to understand whats the ability of the node to handle the work thats being sent its way, rather than just whether it's up or not.
A large percentage of outages can be avoided by using various graceful degradation techniques. This involves creating some mechanism of applying back pressure to signal that the service is overloaded. One such example is Qalm from Uber.
Back pressure needs to be propagated all the way up the call chain, if its not there would be some degree of queuing at some component of the ecosystem.
So yes, build some backpressure in your normal workflow is one way to indicate distress while not making a bad situation worse.
Health lies in the eye of the client
From Steve Yegge's famous platform rant
monitoring and QA are the same thing. You'd never think so until you try doing a big SOA. But when your service says "oh yes, I'm fine", it may well be the case that the only thing still functioning in the server is the little component that knows how to say "I'm fine, roger roger, over and out" in a cheery droid voice. In order to tell whether the service is actually responding, you have to make individual calls. The problem continues recursively until your monitoring is doing comprehensive semantics checking of your entire range of services and data, at which point it's indistinguishable from automated QA. So they're a continuum.
If the perception of a service's health is completely internal it will miss a lot of outages. One of the most common things I advise developers to do when setting up SLOs for their service is to set it up from the client perspective. A very similar point is also made in the Metrics that Matter talk from Google.

If you are to take away anything from this, remember to instrument your metrics from the client side, those are the ones that really matter.
Measuring Service Health
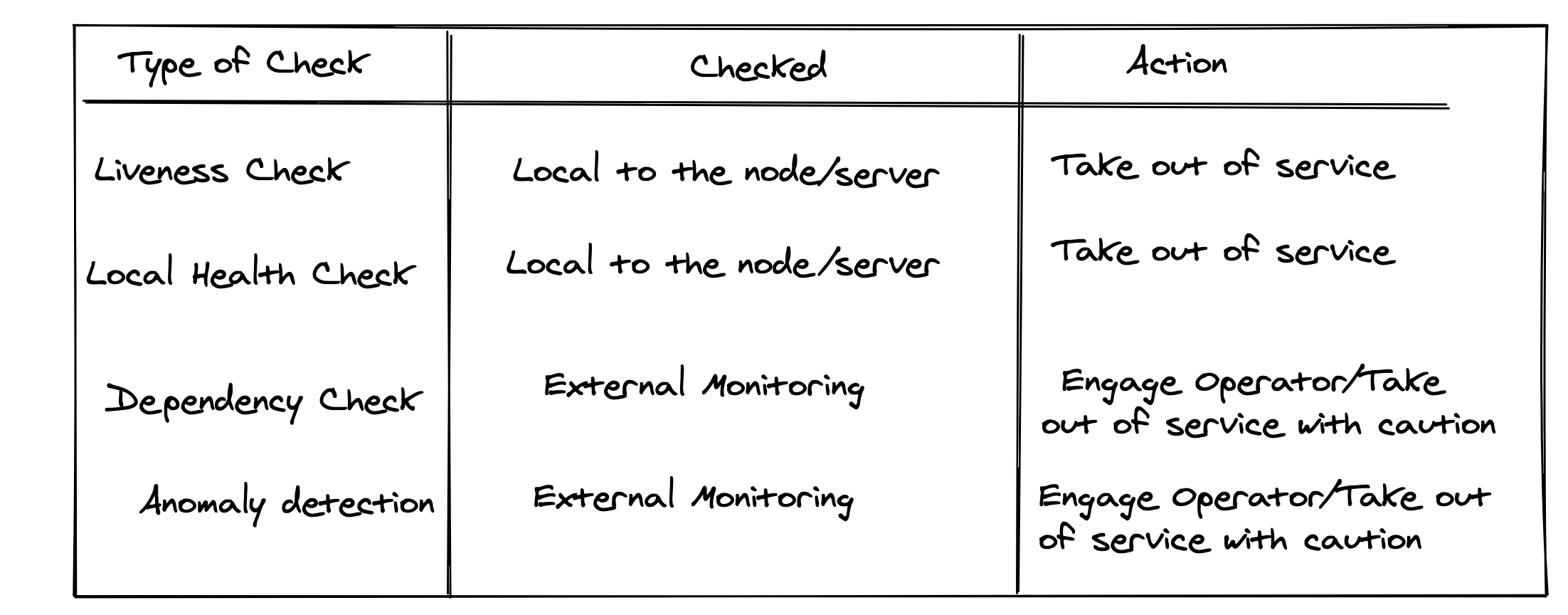
So, how do we think about service health and health checks. The Amazon Builder's Library again gives us a great framework around this. The define 4 kinds of health checks:
Liveness Checks: These test for basic connectivity and the presence of a server process.
Local Health Checks: These check resources which are not shared by the peers of the server. (So, no dependency checks). Examples include checking the ability to do disk I/O, checking supporting daemon processes which put functionality at risk in subtle, difficult to detect ways.
Dependency Health Checks: These checks check for the ability of the server to communicate with dependencies, if any metadata that is consumed by the server is stale or other issues. If any automation is built around the dependency health checks, the right amount of thresholding needs to be built in to prevent the automation from taking any drastic action unexpectedly.
Anomaly Detection: These check for if a server is misbehaving compared to its peers. Examples include clock skew, old code running, extra reported latency etc.
The first two are good candidates for a traditional /health endpoints. The latter two are health checks which are performed from a point of view that is external to the service. These are good candidates to monitor and alert some human operator on.
I think that settles the debate, at least in my in my head, about service health checks